通知公告
DeepSeek AI4RUC系列课程第二讲,探索学科大模型构建之路
发布时间:2025-03-01
2月28日下午,由中国人民大学国家治理大数据和人工智能创新平台(简称“创新平台”)、新时代智慧治理学科交叉中心、交叉科学研究院和教务处主办的DeepSeek AI4RUC系列课程举办第二讲。本讲主题为《RAG、大模型微调实践与构建学科大模型的思考》,由创新平台工程师王安顶主讲。该系列课程旨在通过技术培训与案例分享,推动全校师生利用DeepSeek等AI工具实现跨学科科研创新。



课程采用大研讨室+四个小会议室同步直播的方式进行
主讲人简介

王安顶
国家治理大数据和人工智能创新平台工程师
技术领域:数据库,多模态数据处理分析,大模型应用
项目经验:大模型质性资料分析与应用,基于多模态大模型的人类学影像分析,价值观调查与智能体模拟
内容回顾
1、课程聚焦普及与应用双路径
王安顶从大模型的发展历程与原理简介、RAG技术原理与实践、大模型微调、学科大模型的思考四个方面讲解了技术原理,并现场带领同步操作。
2、大模型的发展历程与原理简介

2.1、从统计模型到通用智能的跨越
大模型(Large Model)是指在深度学习中具有大量参数和复杂结构的机器学习模型,凭借数亿至数千亿参数规模,实现了从单一任务处理到通用智能的跨越。其发展历程可分为四个阶段,用白话去做一些形象的比喻:
统计语言模型(SLM,1990年代):像背单词书,靠概率猜下一个词。
神经语言模型(NLM,2013年):学会联系上下文,但记忆短暂。
预训练语言模型(PLM,2018年):突破长程依赖,理解整段语义。
大语言模型(LLM,2020年后):海量参数+自注意力机制,实现“思维涌现”。


2.2、分类与应用场景
按领域:
语言大模型:专注文本生成与理解(GPT系列、BERT、T5)。
视觉大模型:处理图像分类与目标检测(ViT、ResNet)。
多模态大模型:融合文本、图像、音频(如CLIP、DALL-E)。
按规模:
通用大模型:可以在多个领域和任务上通用的大模型,具有较强的泛化能力,相当于AI的“通识教育”。
行业大模型:针对特定行业或领域进行优化的大模型,通常使用行业相关的数据进行预训练或微调,从而提供更精准的结果。
垂直大模型:专注于某一行业特定任务或场景的大模型,通常使用任务相关的数据进行训练。
3、RAG技术原理与实践
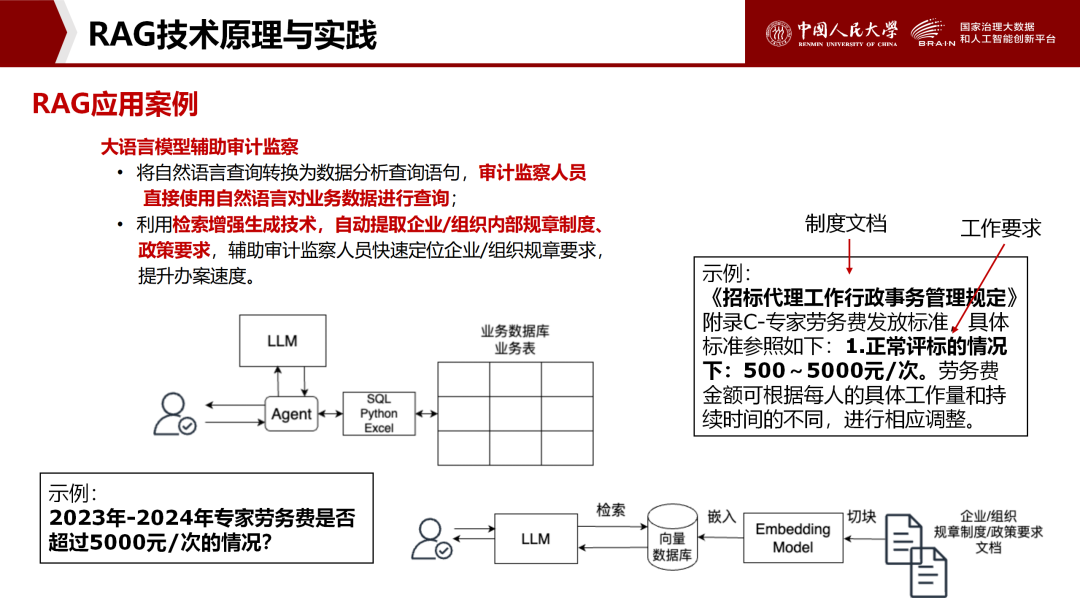
解决大语言模型的局限性:知识不是实时的、对私有领域的知识不了解、幻觉问题,RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合了信息检索技术与语言生成模型的人工智能技术。该技术通过从外部知识库中检索相关信息,以增强模型处理知识密集型任务的能力。
王安顶老师通过人大特色知识库、智能审计两个案例生动介绍了RAG的应用,并手把手教授以“Anything LLM+Ollama+DeepSeek R1”方式搭建知识库。
4、大模型微调:低成本实现专业化

4.1、为何需要微调?
领域适配:通用模型缺乏专业场景理解(如法律文书生成)。
数据补充:行业数据(如医疗病例)未包含在预训练集中。
成本优化:微调仅需1%-10%的预训练资源,响应速度更快。

4.2、需要微调的场景
特定任务需求:如医疗、金融、法律等,微调可以帮助模型学习行业特有的术语和知识。
数据集较小的情况:当可用的数据集较小且与预训练模型的任务存在较大差异时,微调可以帮助模型更好地适应新任务。通过使用特定领域的数据进行微调,模型能够在小样本情况下提高对当前专业的处理性能。
语言风格和个性化需求:希望模型生成的文本具有特定的语言风格或个性。
提高模型的准确性和泛化能力:当现有模型在特定任务上的表现不理想时,微调可以通过引入新的数据和任务特定的训练来提升模型的准确性和泛化能力。
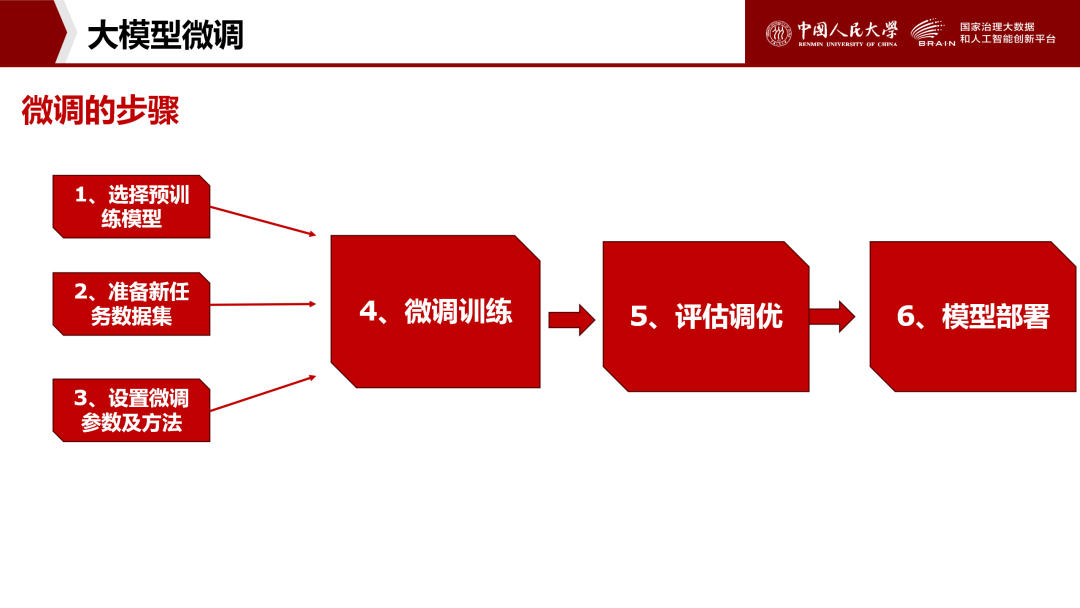
4.3、微调的步骤
选择预训练模型:选择一个在大规模数据集上预训练好的模型,如BERT、GPT等。
准备新任务数据集:收集并处理与特定任务相关的数据集,包括训练集、验证集和测试集。
设置微调参数及方法:根据任务特性和模型特点,设置合适的微调参数,如学习率、批处理大小、训练轮次等。
进行微调训练:在新任务数据集上对预训练模型进行进一步训练,通过调整模型权重和参数来优化模型在新任务上的性能。
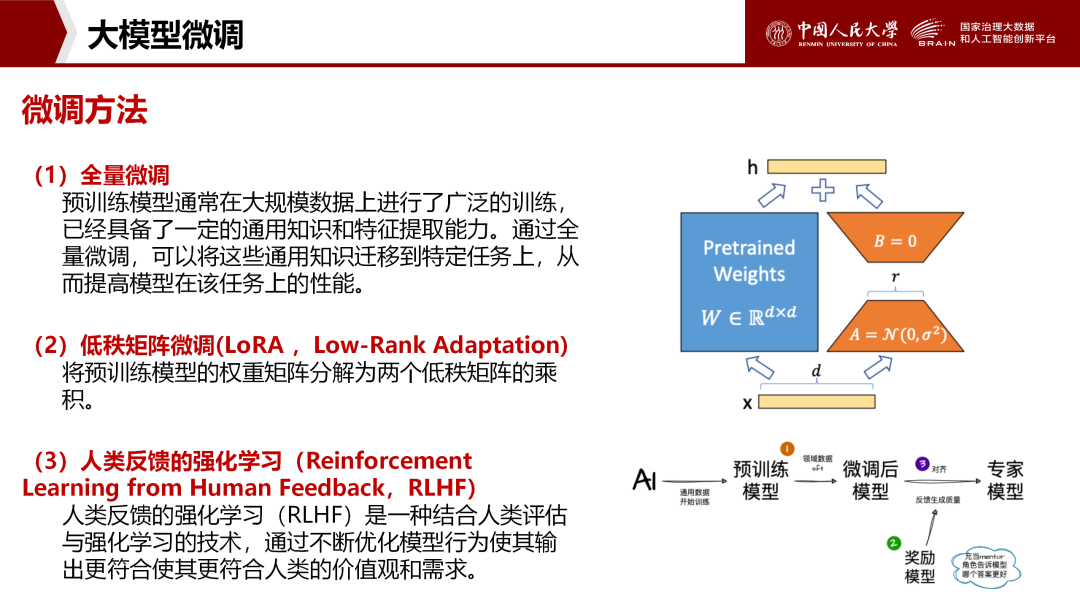
4.4、微调方法
全量微调:调整所有参数,适合算力充足的场景。
低秩矩阵微调(LoRA):将权重矩阵分解为低秩乘积,以5%参数量实现90%性能,适合资源受限场景。
人类反馈强化学习(RLHF):通过人类评分优化输出合规性(如避免生成敏感内容)。
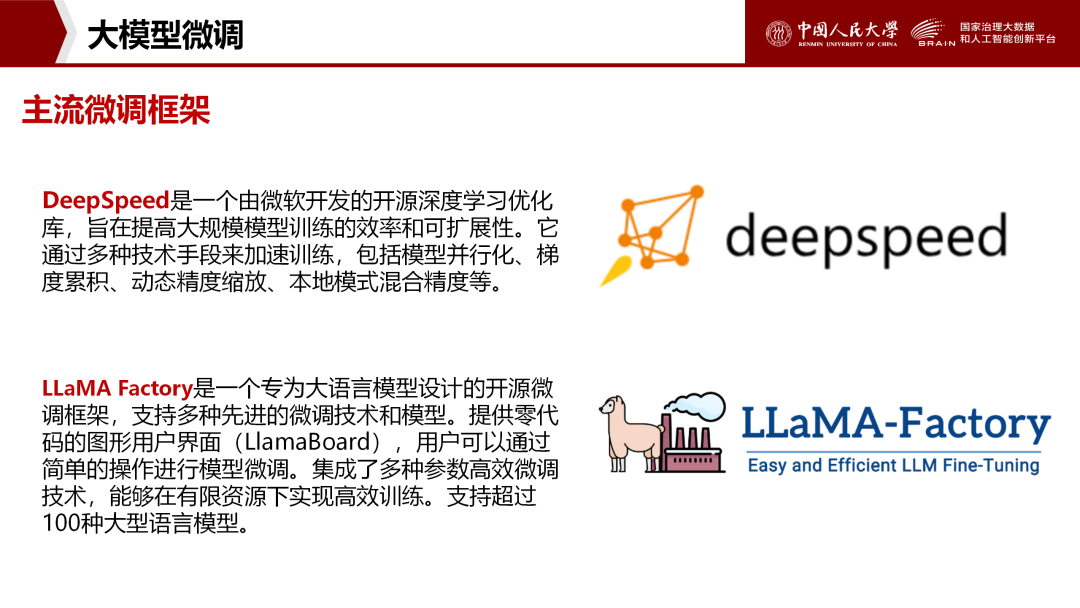
4.5、主流微调框架:
DeepSpeed:微软开源框架,支持大规模分布式训练与混合精度计算。
LLaMA Factory:零代码图形界面,覆盖100+大模型,支持快速微调。

4.6、微调数据集的构造
人工生成数据集
根据需求构建:人工设计指令和回答,确保质量和专业性。如医疗领域由专家编写指令。但成本高,耗时长。
抓取真实数据:从论坛、问答社区等抓取用户问答,反映真实需求。需注意版权和隐私,需筛选和清洗数据。
模型构建数据集
Self-Instruct:模型自身生成指令和回答,快速生成大量数据。但质量参差不齐,需筛选和优化。
人类与LLM互动数据:收集人类与模型互动记录,帮助模型理解人类意图。如聊天机器人对话记录。
多个LLM代理对话:不同LLM代理扮演角色对话,生成多样对话数据。如老师和学生问答对话。
现有数据集的收集和改进
收集公开数据集:从互联网收集已公开的数据集,可能已处理和标注,可直接使用或改进。
改进现有数据集:清洗去除低质量数据,标注添加信息,扩展增加指令和回答对,提高质量和适用性。
采用多种方法创建的数据集
采用多种方法创建的数据集:综合人工生成、模型生成、现有数据集等方法,创建丰富高质量数据集。需协调好不同方法关系,确保一致性和连贯性。
5、学科大模型:人文社科研究的智能革新路径

当前通用大模型在人文社科领域的应用存在三重脱节:首先,基于西方语料训练的模型难以准确解析中国特色的政治话语体系(如"全过程人民民主"与"人类命运共同体");其次,人文社科理论体系适配性不足,易产生专业术语混淆(如物权法与产权制度的概念错位);第三,数据合规性存在隐患,涉及舆情分析、政策模拟等场景时,通用模型难以满足本地化存储与数据主权要求。这种"技术-学科"的错位,催生了垂直领域模型的构建需求。
然而,学科大模型构建面临多重技术-学术耦合难题:
技术与资源瓶颈:数据标注依赖领域专家(如古籍文献解析),人力与时间成本高昂;亿级参数训练需数千万预算,算力门槛陡增;小众学科数据稀疏导致的“长尾问题”可能引发模型失衡。
学术伦理红线:训练数据的学派失衡可能导致学术立场固化。如果模型的训练数据过度依赖某一学派的文献,可能削弱其多元视角和批判性思维能力。
敏感内容争议:模型对敏感事件的自动生成内容可能引发争议,涉及信息准确性、立场偏见及社会影响等问题。
学科大模型正展现出多维度的应用潜能:在学术研究中,模型可自动挖掘古籍文献的历史关联,或基于社会调查数据构建虚拟社会仿真模型,助力理论创新;在教学场景中,生成个性化培养方案,提升学生“社会学+计算科学”跨学科能力;在政策评估中,智能解析地方政府工作报告,识别执行偏差与风险点(如乡村振兴资金分配不均),为科学决策提供支持。
未来,学科大模型需持续探索技术与人文伦理的平衡——既深入学术逻辑,又坚守伦理底线,最终成为兼具智能深度与文化温度的学术伙伴。
6、问答环节
课程结束后,现场主要围绕模型部署的具体实践进行问答,同学们基于本次实操经历,提出了更多实际操作的问题,探索从‘AI旁观者’向‘技术实践者’的进一步跨越。
7、下期预告
DeepSeek在法学领域的应用
DeepSeek AI4RUC系列课程简介
DeepSeek AI4RUC系列课程旨在提供技术支持及案例参考,助力全校师生使用DeepSeek等先进工具开展科研实践。由创新平台、子实验室及数据科学领域相关专家授课。通过真实交叉项目案例分享,普及并深化人工智能在科研中的应用。课程分为普及和应用两个部分,普及部分采用“白话聊DeepSeek”的形式,让人文社科师生也能够轻松掌握DeepSeek的部署与使用;应用部分则聚焦数据标注、模型训练等技术,结合创新平台实际开展的前沿项目,如教育部国家人才供需匹配、政策评估与执行分析、智慧审计和纪检监察、质性数据管理分析等。激发更多跨学科的研究思路与实践应用,推动科研创新的深度融合。
