通知公告
DeepSeek AI4RUC系列课程首讲开启,打造智能人大"方法论工具箱"
发布时间:2025-02-21
2月21日下午,由中国人民大学国家治理大数据和人工智能创新平台(简称“创新平台”)、新时代智慧治理学科交叉中心、交叉科学研究院和教务处主办的DeepSeek AI4RUC系列课程首场讲座正式开讲。本讲主题为《DeepSeek简介与应用启示》,由创新平台工程师张耀元主讲。该系列课程旨在通过技术培训与案例分享,推动全校师生利用DeepSeek等AI工具实现跨学科科研创新。


课程采用大研讨室+小会议室同步直播的方式进行
主讲人简介

张耀元
国家治理大数据和人工智能创新平台工程师
技术领域:统计学,大语言模型落地应用,探索性数据分析与属性数据分析,因果推断。
项目经验:农产品价格预测,text2sql,RAG&LLM,医疗与健康数据处理分析及可视化。
内容回顾
1、课程聚焦普及与应用双路径
课程分为普及与应用两大模块:
普及部分:以“白话聊DeepSeek”形式,降低人文社科师生使用门槛,涵盖模型部署与基础操作;
应用部分:结合数据标注、模型训练等技术,围绕教育部国家人才供需匹配、政策评估、智慧审计等前沿项目案例,探索AI与科研深度融合。
2、DeepSeek技术演进
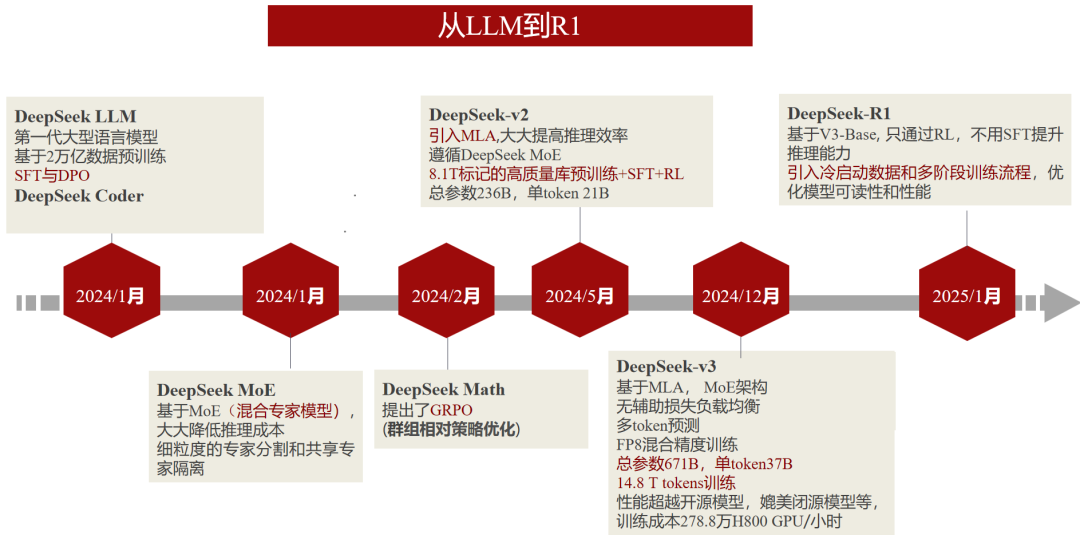
图源:苏州人工智能学院
张耀元系统梳理了DeepSeek系列模型的发展历程与技术亮点:
DeepSeek LLM(2024年):基于2万亿数据预训练,引入有监督微调(SFT)与直接偏好优化(DPO),奠定基础能力;
DeepSeek Coder(2024年):专攻代码生成与补全;
DeepSeek-Math(2024年):创新GRPO算法,解决复杂数学推理问题,性能较传统PPO算法更全面;
DeepSeek-v2/v3(2024-2025年):结合混合专家模型(MoE)与多层级注意力(MLA),参数规模达千亿级,训练效率提升显著;
DeepSeek-R1(2025年):通过强化学习优化推理能力,引入冷启动数据与多阶段训练,提升响应质量。
3、关键技术通俗解读

冷启动数据:类比“智能音箱初学用户偏好”,为模型提供初始高质量数据,加速基础能力构建;
想象一下,你买了一台全新的智能音箱(比如天猫精灵或小度)。当你第一次开机时,它对你一无所知——不知道你喜欢听什么音乐、习惯几点起床、喜欢什么类型的新闻。为了让音箱更好地为你服务,你需要先“教”它一些基本的东西,比如设置你的音乐偏好、作息时间等。这些初始的数据,就是冷启动数据。在AI模型中,冷启动数据指的是模型在初始阶段使用的少量但高质量的数据,用来帮助模型快速学习基本的任务能力。没有这些数据,模型就像一张白纸,完全不知道从哪里开始。冷启动数据可以看做给AI模型的“入门教程”,帮助它快速掌握基本技能,为后续的复杂任务打下基础。没有它,模型就像是一个完全不懂行的新手,需要花更多时间和资源去摸索。
长思维链(COT)数据:强调逻辑推理过程训练,使模型学会“如何思考”而非仅记忆答案;
想象一下,你在教一个小朋友解决一道复杂的数学题。这道题需要分好几步来完成,比如先理解题意,然后列公式,接着计算,最后验证答案。如果小朋友只记住最后的结果,而没有学会中间的步骤,下次遇到类似的题目,他可能还是不会做。长思维链数据就是用来训练AI模型的数据,它包含了解决问题的详细步骤和逻辑推理过程,而不仅仅是最终的答案。这些数据帮助模型学会“如何思考”,而不是简单地“记住答案”。
蒸馏技术:通过“教师模型”提升“学生模型”的性能,共享优化资源,降低重复训练成本,推动行业协作。
想象一下,你有一个超级学霸朋友(比如大模型ChatGPT),他考试总能考满分,但缺点是饭量超大(需要顶级算力)、做题超慢(推理速度低),而且只愿意亲自做题(无法直接复制他的大脑)。现在你想培养一个“小学霸”(轻量小模型),让它能像大学霸一样厉害,但吃得少、做题快,还能装进手机里用。怎么办?蒸馏技术就是直接让大学霸当老师!具体分三步:
1、学霸做题:让大学霸做一堆题(比如翻译句子、写文章),不仅写答案,还要写下详细解题思路(输出逻辑、概率分布等“软知识”)。
2、提炼重点:把大学霸的解题思路整理成“精华笔记”(知识提炼),去掉复杂细节,保留核心逻辑。
3、教小学霸:让小学霸一边看原题,一边对照“精华笔记”学习,目标是答案接近学霸,但用更简单的方法(模型结构更小)。
4、跨学科应用案例:法学研究显成效

创新平台工程师尹珺的研究案例表明,DeepSeek在法学领域展现自发法律推理能力。例如,未明确提示法律框架时,模型仍能生成包含“大前提-小前提”逻辑链的结论,凸显其长思维链强化学习的优势。
5、部署需求与硬件支持
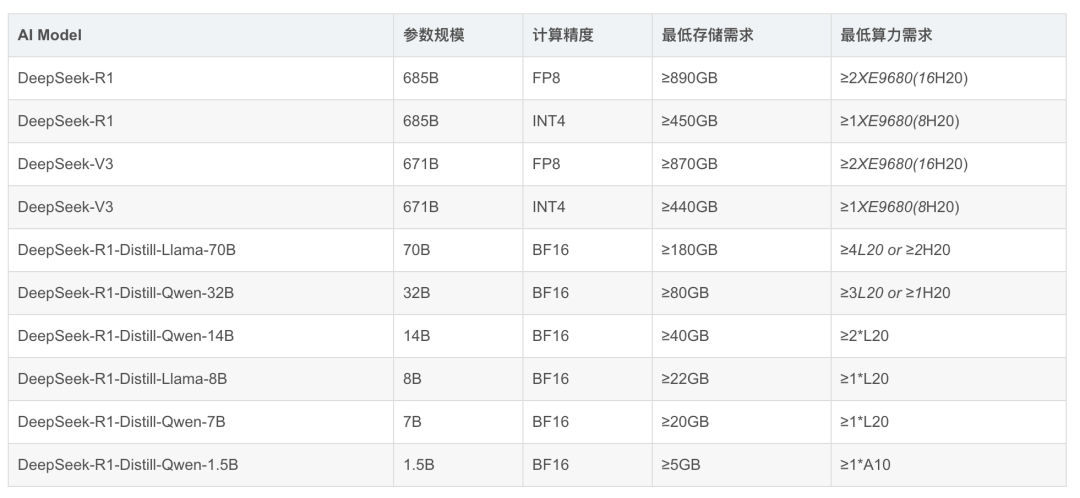
上表中描述了不同型号的 DeepSeek 系列 AI 模型的参数规模、计算精度、最低存储需求和最低算力需求。影响AI推理(inference)场景GPU算力需求的主要因素:模型参数规模、计算精度(BF16/FP8/INT8/INT4)、输入及输出上下文长度、并发用户数、延迟要求(TTFT/TPOT)、推理框架的效率等。表达式的具体含义比如“≥2XE9680(16H20)” 表示:
硬件数量:至少需要 2 台 PowerEdge XE9680 服务器,每台配备8个H20 GPU,总计16个 H20 GPU。NVIDIA H20 是针对 AI 训练和推理优化的 GPU,其显存容量:96GB,高于 A800 的 80GB,适合处理大模型和长序列任务。显存带宽:较 A800 提升近一倍,支持更高吞吐量。
6、问答环节
在本次会议的问答环节中,在场师生围绕本地部署、模型能力、知识库管理、费用成本等问题展开了深入讨论。张耀元结合具体操作、技术原理、datahub(云端大数据平台)功能、工具推荐等多角度进行了详细解答。
目前,中国人民大学校级计算平台已成功部署满血版DeepSeek 671B模型,后续根据算力情况逐步开放给校内师生使用。
7、展望:AI4Research新范式
首讲为师生揭开了DeepSeek的技术面纱,未来课程将持续分享AI在质性数据分析、政策仿真等场景的应用,推动跨学科科研创新。通过工具赋能与思维革新,DeepSeek或将成为高校科研智能化转型的核心引擎。
为方便大家部署本地私有化大模型,创新平台已将Qwen0.5b、Qwen7b、Qwen72b模型的部署与微调步骤和DeepSeek-r1-Distill-7B模型的部署操作说明上传至创新平台的数据港官网,助力更多研究者探索AI4Research的无限可能。
平台网址:https://datahub.ruc.edu.cn/org-portal/RUC/
8、下期预告
DeepSeek在法学领域的应用
DeepSeek AI4RUC系列课程简介
DeepSeek AI4RUC系列课程旨在提供技术支持及案例参考,助力全校师生使用DeepSeek等先进工具开展科研实践。由创新平台、子实验室及数据科学领域相关专家授课。通过真实交叉项目案例分享,普及并深化人工智能在科研中的应用。课程分为普及和应用两个部分,普及部分采用“白话聊DeepSeek”的形式,让人文社科师生也能够轻松掌握DeepSeek的部署与使用;应用部分则聚焦数据标注、模型训练等技术,结合创新平台实际开展的前沿项目,如教育部国家人才供需匹配、政策评估与执行分析、智慧审计和纪检监察、质性数据管理分析等。激发更多跨学科的研究思路与实践应用,推动科研创新的深度融合。
