技术培训:多模态大语言模型在人类学影像库的应用
发布时间:2024-11-229月24日上午,人类学影像库数据分析技术培训在国家治理大数据和人工智能创新平台(简称“创新平台”)举办。培训基于创新平台社会学院基层与社会治理质性资料数据子实验室项目,讲解多模态大语言模型的技术原理以及在人类学影像库中的应用。由创新平台工程师王安顶老师,和人类学专业硕士生赵璐楠联合讲授,为在场同学带来人文社会科学和大数据、人工智能技术碰撞的精彩一课。

活动回顾
多模态大语言模型(Multimodal Large Language Model)已成为人工智能研究和产业界最活跃的领域之一,培训涉及几块主要内容:从技术角度讲解跨模态学习任务,包括图生文、文生图、跨模态检索;跨模态学习范式,涉及CLIP、BLIP、LLAVA等模型的技术原理;多模态人类学与影像库实操讲解。摘取部分内容见如下:
关于迁移学习与多模态模型基本原理
迁移学习是一种在机器学习中广泛应用的策略,它允许模型将在一个任务中学到的知识应用到另一个相关的任务中。通过训练好模型后,可以将其迁移到特定任务上,如GPT-4可以通过指令微调和交互完成各种任务。同时,通过图像文本配对和用户指令对齐,可以实现不同模态数据的转换和预训练。通过对视觉的编码,通过中间件连接到大语言模型上,实现将不同模态的数据在大语言基础模型上进行处理。

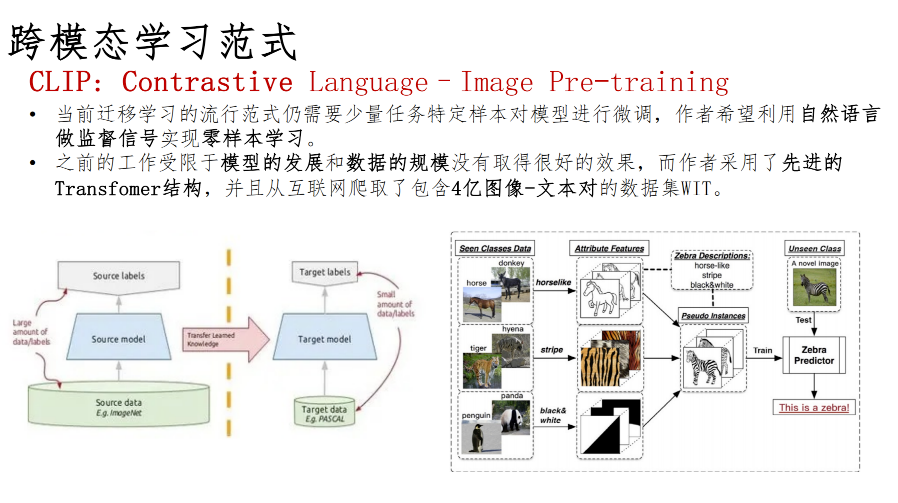
典型的多模态模型-CLIP
CLIP采用了先进的Transfomer结构,并且从互联网爬取了包含4亿图像-文本对的数据集WiT。模型通过海量图像文本对实现图像和文本特征在向量空间上的对齐。
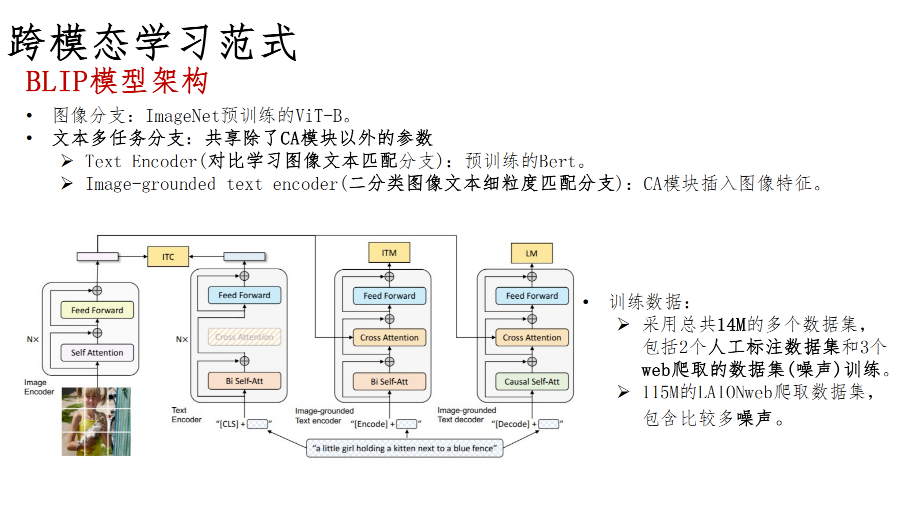
典型的多模态模型-BLIP
BLIP模型训练的数据来自互联网爬取和人工标注,采用多任务分支的架构进行训练实现了图像生成和图像-文本检索的多任务。
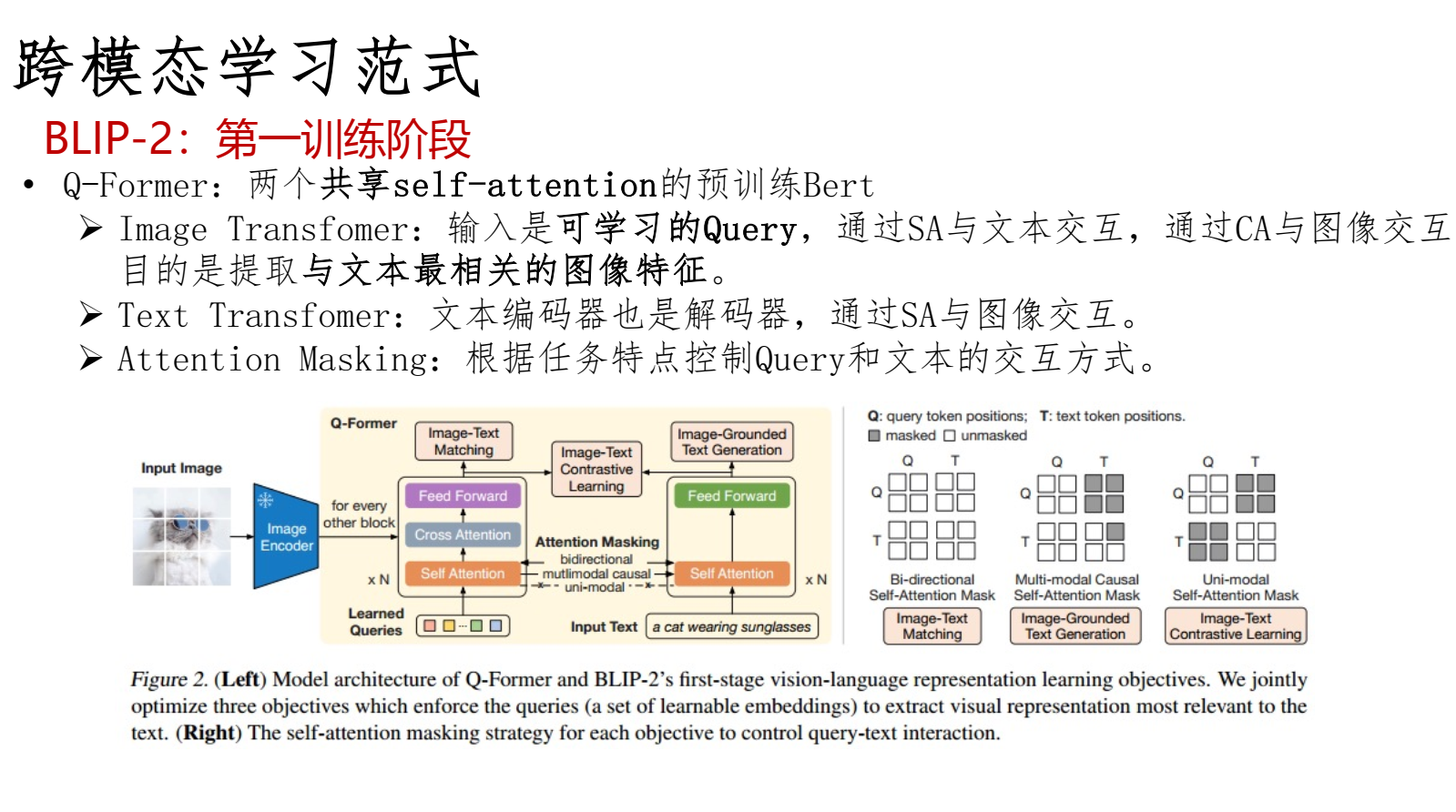
典型的多模态模型-BLIP2
BLIP-2模型采用两阶段训练:第一阶段进行表示学习,使得Q-former学习与文本最相关的视觉表示。第二阶段进行生成学习,使得Q-former学习到的视觉表示能对大语言模型可用。
典型的多模态模型-LLAVA
LLAVA采用GPT根据图像的描述、标注框、few-shot样例生成优质的指令微调数据对模型进行微调。

多模态模型在人类学影像库的应用
人类学影像库的构建流程:从视频切片、大模型识别、场景片段剪辑到场景合并,多模态大模型极大地提升了影像处理的自动化水平。Gemini多模态大模型通过深度学习和跨模态识别技术,能够精准分析影像中的场景和内容,并生成结构化数据。这一技术不仅提升了影像库的处理效率,也为人类学研究提供了全新的工具和视角。

多模态人类学探讨
作为学界比较活跃的人类学分支学科,基于视觉的影视人类学一直走在时代前沿,致力于人类学表征手段的革新,以及人类学理论方法未来发展方向的探索。而多模态人类学(multi-modality anthropology)则是近些年来出现的,以多媒介为展示和分析路径,呈现并反思多感官体验,最终达到多主体对话和多方合作的人类学新形态。(富晓星.多模态视域下的影视人类学及其示范意义)
在人工智能时代,影视人类学开始尝试运用最新的多模态大语言模型进行视频理解。由此,影视人类学积累的多元社会文化的海量视频数据,通过多模态大语言模型的处理和分析,可快速建立影像资料的元数据库,用于人类学教研和影像与文化的深入分析。

全部讲解之后,人类学专业硕士生赵璐楠进一步抛出问题,带领人文社科同学思考,如何在最大程度上利用好影像库资源与平台,开展多模态人类学与民族志影像分析的进一步探索。

本次培训是一次别开生面的教学尝试,融合了授课形式的革新与内容的深度挖掘,将理工科的技术原理与人文社科的研究命题交织呈现。既让人文社科同学由浅入深了解多模态大模型技术的前沿进展,同时与学科内容深入结合,在交叉融合及碰撞中启发新思考,探索交叉研究新路径。
欢迎人文社科专业老师和同学与创新平台共同探索实践!
